点击进入到lLlama.cpp项目拉取代码,有两种方式根据你自己的情况来进行选择。可以通过gitclone代码又或者下载zip包放入到服务器。
在浏览器或 API 调试工具(如 Postman、curl 等)的地址栏中,输入以下 URL:
请求方法:POST
POST
Body 类型:raw(JSON 格式)
raw
请求体示例:
说明:
model
messages
role
"user"
"assistant"
"system"
确保服务已成功启动并监听对应 IP 和端口,方可正常调用接口。
 0
0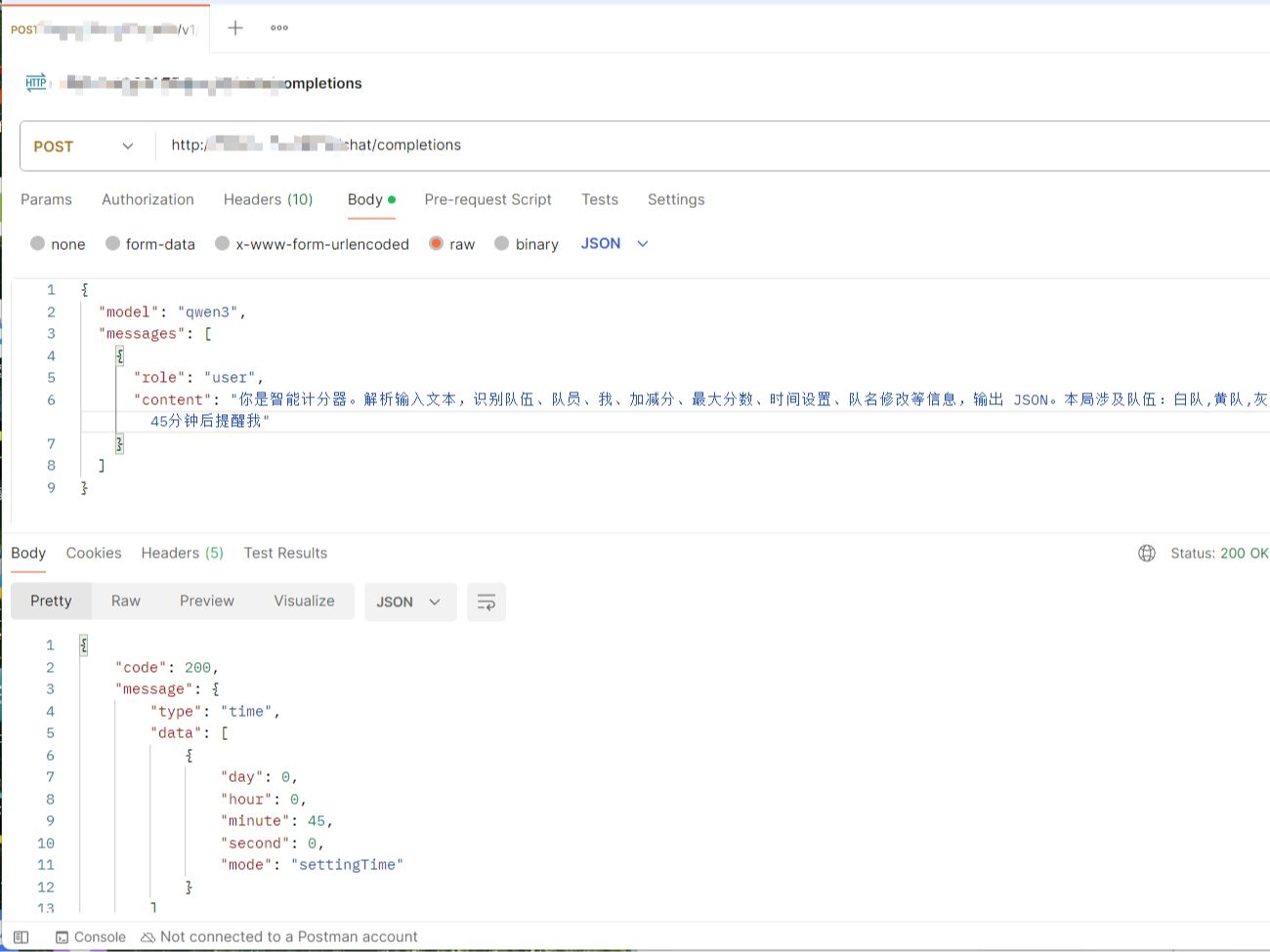












 0
0 0
0 0
0 qq空间
qq空间  微博
微博  复制链接
复制链接